Starting at some level of the hierarchy, the cache becomes shared between different cores. This reduces the total die area and lets you add more cores on a single chip but also poses some “noisy neighbor” problems as it limits the effective cache size and bandwidth available to a single execution thread.
On most CPUs, only the last layer of cache is shared, and not always in a uniform manner. On my machine, there are 8 physical cores, and the size of the L3 cache is 8M, but it is split into two halves: two groups of 4 cores have access to their own 4M region of the L3 cache, and not all of it.
There are even more complex topologies, where accessing certain regions of memory takes non-constant time, different for each core (which is sometimes unintended). Such architectural feature is called non-uniform memory access (NUMA), and it is the case for multi-socket systems that have several separate CPU chips installed.
On Linux, the topology of the memory system can be retrieved with lstopo:
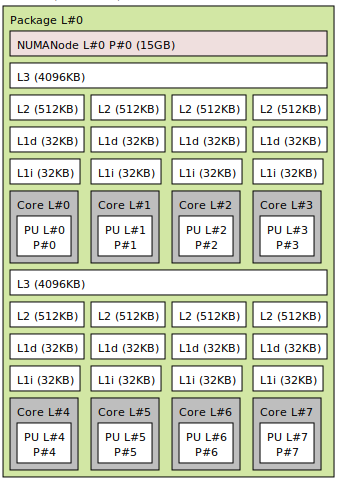
This has some important implications for parallel algorithms: the performance of multi-threaded memory accesses depends on which cores are running which execution threads. To demonstrate this, we will run the bandwidth benchmarks in parallel.
#CPU Affinity
Instead of modifying the source code to run on multiple threads, we can simply run multiple identical processes with GNU parallel. To control which cores are executing them, we set their processor affinity with taskset. This combined command runs 4 processes that can run on the first 4 cores of the CPU:
parallel taskset -c 0,1,2,3 ./run ::: {0..3}
Here is what we get when we change the number of processes running simultaneously:

You can now see that the performance decreases with more processes when the array exceeds the L2 cache (which is private to each core), as the cores start competing for the shared L3 cached and the RAM.
We specifically set all processes to run on the first 4 cores because they have a unified L3 cache. If some of the processes were to be scheduled on the other half of the cores, there would be less contention for the L3 cache. The operating system doesn’t monitor such activities — what a process does is its own private business — so by default, it assigns threads to cores arbitrarily during execution, without caring about cache affinity and only taking into account the core load.
Let’s run another benchmark, but now with pinning the processes to different 4-core groups that don’t share L3 cache:
parallel taskset -c 0,1 ./run ::: {0..1} # L3 cache sharing
parallel taskset -c 0,4 ./run ::: {0..1} # no L3 cache sharing
It performs better — as if there were twice as much L3 cache and RAM bandwidth available:

These issues are especially tricky when benchmarking and are a huge source of noise when timing parallel applications.
#Saturating Bandwidth
When looking at the RAM section of the first graph, it may seem that with more cores, the per-process throughput goes ½, ⅓, ¼, and so on, and the total bandwidth remains constant. But this isn’t quite true: the contention hurts, but a single CPU core usually can’t saturate all of the RAM bandwidth.
If we plot it more carefully, we see that the total bandwidth actually increases with the number of cores — although not proportionally, and eventually approaches its theoretical maximum of ~42.4 GB/s:

Note that we still specify processor affinity: the $k$-threaded run uses the first $k$ cores. This is why we have such a huge performance increase when switching from 4 cores to 5: you can have more RAM bandwidth if the requests go through separate L3 caches.
In general, to achieve maximum bandwidth, you should always split the threads of an application symmetrically.