Consider a strided incrementing loop over an array of size $N=2^{21}$ with a fixed step size of 256:
for (int i = 0; i < N; i += 256)
a[i]++;
And then this one, with the step size of 257:
for (int i = 0; i < N; i += 257)
a[i]++;
Which one will be faster to finish? There are several considerations that come to mind:
- At first, you think that there shouldn’t be much difference, or maybe that the second loop is $\frac{257}{256}$ times faster or so because it does fewer iterations in total.
- Then you recall that 256 is a nice round number, which may have something to do with SIMD or the memory system, so maybe the first one is faster.
But the right answer is very counterintuitive: the second loop is faster — and by a factor of 10.
This isn’t just a single bad step size. The performance degrades for all indices that are multiples of large powers of two:

There is no vectorization or anything, and the two loops produce the same assembly except for the step size. This effect is due only to the memory system, in particular to a feature called cache associativity, which is a peculiar artifact of how CPU caches are implemented in hardware.
#Hardware Caches
When we were studying the memory system theoretically, we discussed different ways one can implement cache eviction policies in software. One particular strategy we focused on was the least recently used (LRU) policy, which is simple and effective but still requires some non-trivial data manipulation.
In the context of hardware, such scheme is called fully associative cache: we have $M$ cells, each capable of holding a cache line corresponding to any of the $N$ total memory locations, and in case of contention, the one not accessed the longest gets kicked out and replaced with the new one.
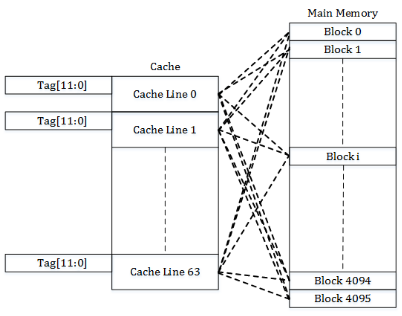
The problem with fully associative cache is that implementing the “find the oldest cache line among millions” operation is pretty hard to do in software and just unfeasible in hardware. You can make a fully associative cache that has 16 entries or so, but managing hundreds of cache lines already becomes either prohibitively expensive or so slow that it’s not worth it.
We can resort to another, much simpler approach: just map each block of 64 bytes in RAM to a single cache line which it can occupy. Say, if we have 4096 blocks in memory and 64 cache lines for them, then each cache line at any time stores the contents of one of $\frac{4096}{64} = 64$ different blocks.
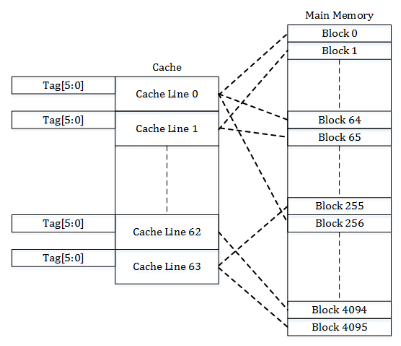
A direct-mapped cache is easy to implement doesn’t require storing any additional meta-information associated with a cache line except its tag (the actual memory location of a cached block). The disadvantage is that the entries can be kicked out too quickly — for example, when bouncing between two addresses that map to the same cache line — leading to lower overall cache utilization.
For that reason, we settle for something in-between direct-mapped and fully associative caches: the set-associative cache. It splits the address space into equal groups, which separately act as small fully-associative caches.
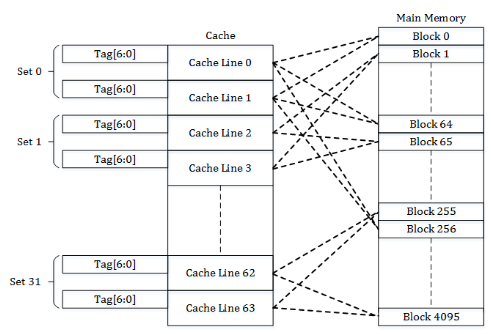
Associativity is the size of these sets, or, in other words, how many different cache lines each data block can be mapped to. Higher associativity allows for more efficient utilization of cache but also increases the cost.
For example, on my CPU, the L3 cache is 16-way set-associative, and there are 4MB available to a single core. This means that there are in total $\frac{2^{22}}{2^{6}} = 2^{16}$ cache lines, which are split into $\frac{2^{16}}{16} = 2^{12}$ groups, each acting as a fully associative cache of their own $(\frac{1}{2^{12}})$-th fraction of the RAM.
Most other CPU caches are also set-associative, including the non-data ones such as the instruction cache and the TLB. The exceptions are small specialized caches that only house 64 or fewer entries — these are usually fully associative.
#Address Translation
There is only one ambiguity remaining: how exactly the cache line mapping is done.
If we implemented set-associative cache in software, we would compute some hash function of the memory block address and then use its value as the cache line index. In hardware, we can’t really do that because it is too slow: for example, for the L1 cache, the latency requirement is 4 or 5 cycles, and even taking a modulo takes around 10-15 cycles, let alone something more sophisticated.
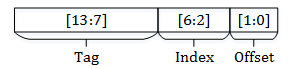
Instead, the hardware uses the lazy approach. It takes the memory address that needs to be accessed and splits it into three parts — from lower bits to higher:
- offset — the index of the word within a 64B cache line ($\log_2 64 = 6$ bits);
- index — the index of the cache line set (the next $12$ bits as there are $2^{12}$ cache lines in the L3 cache);
- tag — the rest of the memory address, which is used to tell the memory blocks stored in the cache lines apart.
In other words, all memory addresses with the same “middle” part map to the same set.
This makes the cache system simpler and cheaper to implement but also susceptible to certain bad access patterns.
#Pathological Mappings
Now, where were we? Oh, yes: the reason why iteration with strides of 256 causes such a terrible slowdown.
When we jump over 256 integers, the pointer always increments by $1024 = 2^{10}$, and the last 10 bits remain the same. Since the cache system uses the lower 6 bits for the offset and the next 12 for the cache line index, we are essentially using just $2^{12 - (10 - 6)} = 2^8$ different sets in the L3 cache instead of $2^{12}$, which has the effect of shrinking our L3 cache by a factor of $2^4 = 16$. The array stops fitting into the L3 cache ($N=2^{21}$) and spills into the order-of-magnitude slower RAM, which causes the performance to decrease.
Performance issues caused by cache associativity effects arise with remarkable frequency in algorithms because, for multiple reasons, programmers just love using powers of two when indexing arrays:
- It is easier to calculate the address for multi-dimensional array accesses if the last dimension is a power of two, as it only requires a binary shift instead of a multiplication.
- It is easier to calculate modulo a power of two, as it can be done with a single bitwise
and. - It is convenient and often even necessary to use power-of-two problem sizes in divide-and-conquer algorithms.
- It is the smallest integer exponent, so using the sequence of increasing powers of two as problem sizes are a popular choice when benchmarking memory-bound algorithms.
- Also, more natural powers of ten are by transitivity divisible by a slightly lower power of two.
This especially often applies to implicit data structures that use a fixed memory layout. For example, binary searching over arrays of size $2^{20}$ takes about ~360ns per query while searching over arrays of size $(2^{20} + 123)$ takes ~300ns. When the array size is a multiple of a large power of two, then the indices of the “hottest” elements, the ones we likely request on the first dozen or so iterations, will also be divisible by some large powers of two and map to the same cache line — kicking each other out and causing a ~20% performance decrease.
Luckily, such issues are more of an anomaly rather than serious problems. The solution is usually simple: avoid iterating in powers of two, make the last dimensions of multi-dimensional arrays a slightly different size or use any other method to insert “holes” in the memory layout, or create some seemingly random bijection between the array indices and the locations where the data is actually stored.