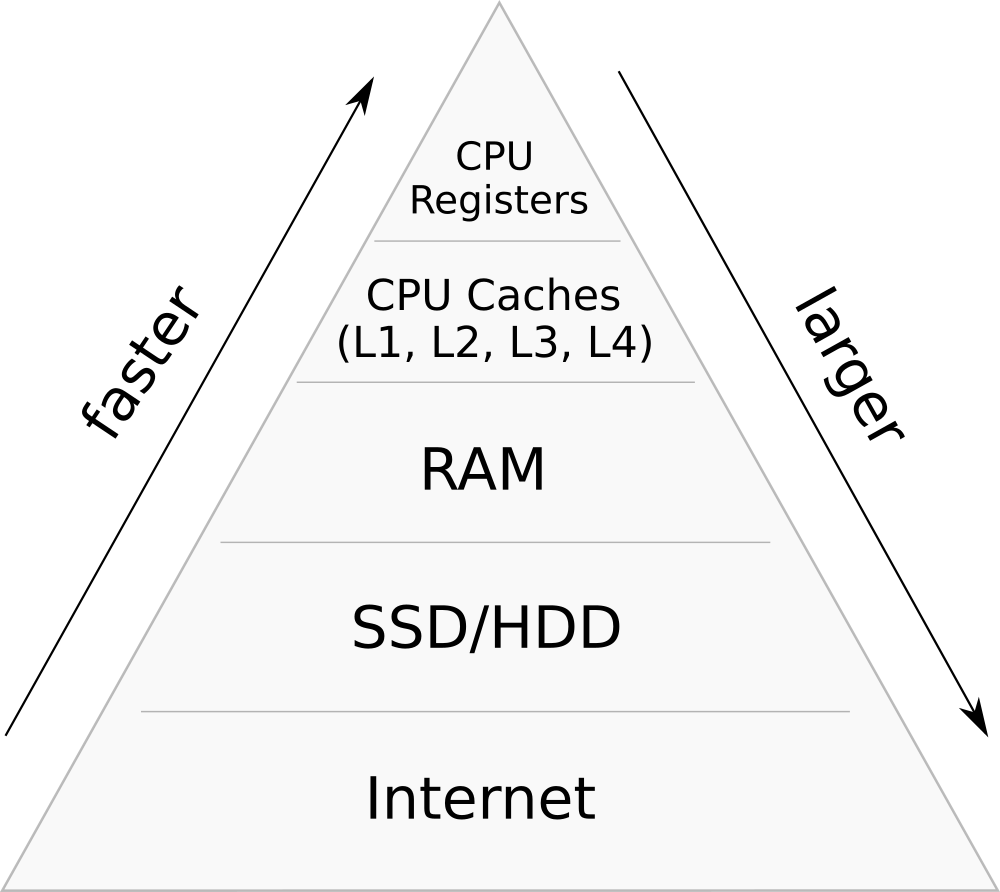
Modern computer memory is highly hierarchical. It consists of multiple cache layers of varying speed and size, where higher levels typically store most frequently accessed data from lower levels to reduce latency: each next level is usually an order of magnitude faster, but also smaller and/or more expensive.
Abstractly, various memory devices can be described as modules that have a certain storage capacity $M$ and can read or write data in blocks of $B$ (not individual bytes!), taking a fixed time to complete.
From this perspective, each type of memory has a few important characteristics:
- total size $M$;
- block size $B$;
- latency, that is, how much time it takes to fetch one byte;
- bandwidth, which may be higher than just the block size times latency, meaning that I/O operations can “overlap”;
- cost in the amortized sense, including the price for the chip, its energy requirements, maintenance, and so on.
Here is an approximate comparison table for commodity hardware in 2021:
| Type | $M$ | $B$ | Latency | Bandwidth | $/GB/mo1 |
|---|---|---|---|---|---|
| L1 | 10K | 64B | 2ns | 80G/s | - |
| L2 | 100K | 64B | 5ns | 40G/s | - |
| L3 | 1M/core | 64B | 20ns | 20G/s | - |
| RAM | GBs | 64B | 100ns | 10G/s | 1.5 |
| SSD | TBs | 4K | 0.1ms | 5G/s | 0.17 |
| HDD | TBs | - | 10ms | 1G/s | 0.04 |
| S3 | $\infty$ | - | 150ms | $\infty$ | 0.022 |
In reality, there are many specifics about each type of memory, which we will now go through.
#Volatile Memory
Everything up to the RAM level is called volatile memory because it does not persist data in case of a power shortage and other disasters. It is fast, which is why it is used to store temporary data while the computer is powered.
From fastest to slowest:
- CPU registers, which are the zero-time access data cells CPU uses to store all its intermediate values, can also be thought of as a memory type. There is only a limited number of them (e.g., just 16 “general purpose” ones), and in some cases, you may want to use all of them for performance reasons.
- CPU caches. Modern CPUs have multiple layers of cache (L1, L2, often L3, and rarely even L4). The lowest layer is shared between cores and is usually scaled with their number (e.g., a 10-core CPU should have around 10M of L3 cache).
- Random access memory, which is the first scalable type of memory: nowadays you can rent machines with half a terabyte of RAM on the public clouds. This is the one where most of your working data is supposed to be stored.
The CPU cache system has an important concept of a cache line, which is the basic unit of data transfer between the CPU and the RAM. The size of a cache line is 64 bytes on most architectures, meaning that all main memory is divided into blocks of 64 bytes, and whenever you request (read or write) a single byte, you are also fetching all its 63 cache line neighbors whether your want them or not.
Caching on the CPU level happens automatically based on the last access times of cache lines. When accessed, the contents of a cache line are emplaced onto the lowest cache layer and then gradually evicted to higher levels unless accessed again in time. The programmer can’t control this process explicitly, but it is worthwhile to study how it works in detail, which we will do in the next chapter.
#Non-Volatile Memory
While the data cells in CPU caches and the RAM only gently store just a few electrons (that periodically leak and need to be periodically refreshed), the data cells in non-volatile memory types store hundreds of them. This lets the data persist for prolonged periods of time without power but comes at the cost of performance and durability — because when you have more electrons, you also have more opportunities for them to collide with silicon atoms.
There are many ways to store data in a persistent way, but these are the main ones from a programmer’s perspective:
- Solid state drives. These have relatively low latency on the order of 0.1ms ($10^5$ ns), but they also have a high cost, amplified by the fact that they have limited lifespans as each cell can only be written to a limited number of times. This is what mobile devices and most laptops use because they are compact and have no moving parts.
- Hard disk drives are unusual because they are actually rotating physical disks with a read/write head attached to them. To read a memory location, you need to wait until the disk rotates to the right position and then very precisely move the head to it. This results in some very weird access patterns where reading one byte randomly may take the same time as reading the next 1MB of data — which is usually on the order of milliseconds. Since this is the only part of a computer, except for the cooling system, that has mechanically moving parts, hard disks break quite often (with the average lifespan of ~3 years for a data center HDD).
- Network-attached storage, which is the practice of using other networked devices to store data on them. There are two distinctive types. The first one is the Network File System (NFS), which is a protocol for mounting the file system of another computer over the network. The other is API-based distributed storage systems, most famously Amazon S3, that are backed by a fleet of storage-optimized machines of a public cloud, typically using cheap HDDs or some more exotic storage types internally. While NFS can sometimes work even faster than HDD if it is located in the same data center, object storage in the public cloud usually has latencies of 50-100ms. They are typically highly distributed and replicated for better availability.
Since SDD/HDD are noticeably slower than RAM, everything on or below this level is usually called external memory.
Unlike the CPU caches, external memory can be explicitly controlled. This is useful in many cases, but most programmers just want to abstract away from it and use it as an extension of the main memory, and operating systems have the capability to do so by the means of virtual memory.
Pricing information is taken from the Google Cloud Platform. ↩︎
Cloud storage typically has multiple tiers, becoming progressively cheaper if you access the data less frequently. ↩︎